УДК 007.681.5:519.714:519.766
АТРИБУЦИЯ
ТЕКСТОВ, КАК ОБОБЩЕННАЯ ЗАДАЧА
ИДЕНТИФИКАЦИИ И ПРОГНОЗИРОВАНИЯ
Луценко
Е.В. - д.э.н., доцент
Кубанский
государственный аграрный университет
Вербальные описания объектов реальности на естественном
языке рассматриваются в статье как их иерархические лингвистические
модели. Предлагается методика и автоматизированная технология,
основанная на применении универсальной когнитивной аналитической
системы "Эйдос", обеспечивающие: автоматизированную
формализацию предметной области на основе вербального описания
ее объектов, автоматизированное формирование описательных
шкал и градаций, а также обучающей выборки, синтез семантической
информационной модели, ее оптимизацию, проверку адекватности
и анализ. Предлагаемые технологии обеспечивают значительную
экономию труда и времени по сравнению с традиционным подходом.
Рассмотрим классическую тестовую задачу
для систем искусственного интеллекта, предложенную Рышардом
Михальски и Джеймсом Ларсоном и подробно описанную на страницах
205-208 в книге Д.Мичи и Р.Джонстона "Компьютер – творец" [1].
Суть этой задачи сводится к тому,
чтобы выработать правила, обеспечивающие идентификацию железнодорожных
составов и прогнозирование направления их следования на основе
их формализованных или вербальных описаний.
Выбор данной задачи не накладывает
ограничений на выводы, полученные в результате ее исследования.
Это обусловлено тем, что она имеет ряд характерных особенностей,
наблюдающихся в подобных задачах в самых различных предметных
областях, т.е. по сути данная задача с полным основанием может
рассматриваться как типовая для широкого класса задач идентификации
и прогнозирования.
Эти особенности состоят в следующем:
1. Имеется ряд объектов, имеющих сложную
многоуровневую структуру признаков.
2. Для каждого из этих объектов известно,
к каким обобщенным категориям (классам) он относится.
3. Необходимо сформировать модель,
обеспечивающую как идентификацию объектов, так и определение
их принадлежности к обобщенным классам.
Если признаки и классы относятся к
одному времени, то имеет место задача идентификации (распознавания).
Если же признаки (факторы, причины) относятся к прошлому, а
классы, характеризующие состояния объектов – к будущему, то
это задача прогнозирования. Математически эти задачи не отличаются.
Существуют различные подходы к решению
данной задачи различаются способами формализации предметной
области, объектов обучающей выборки и синтеза математической
модели.
В данной статье мы рассмотрим два
основных подхода:
1. "Классический", т.е.
основанный на изучении объектов предметной области экспертами
(когнитивный анализ), выделении признаков объектов и формирования
описательных шкал и градаций, в которых шкалам и градациям
соответствуют уникальные коды.
2. "Лингвистический", в
котором вербальные описания объектов предметной области на
естественном языке используются для автоматизированной формализации
предметной области, формирования обучающей выборки и синтеза
модели.
Кратко рассмотрим реализацию обоих
этих подходов в интеллектуальной технологии "Эйдос" [1].
Исходные данные к задаче представлены в графической форме
(рисунок 1).
|

|
|
Рисунок 1. Примеры поездов, идущих
на запад и на восток. |
Железнодорожный состав является сложным
объектом, имеющим несколько иерархических уровней и допускающим,
соответственно, несколько уровней описания. Некоторые из этих
уровней представлены в таблице 1:
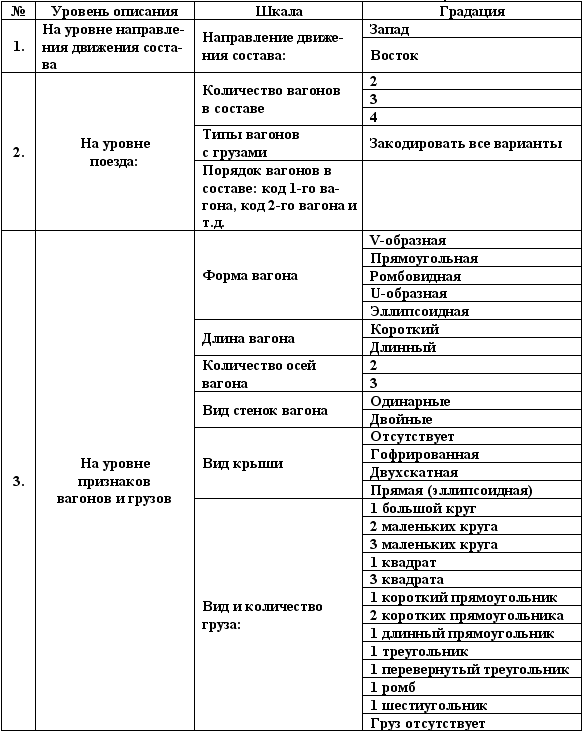
Таблица 1 – УРОВНИ ОПИСАНИЯ ЖЕЛЕЗНОДОРОЖНЫХ СОСТАВОВ
Можно, например, описывать составы
с использованием шкал только 2-го уровня или только 3-го уровня.
Возможны и смешанные варианты.
1-й вариант соответствует гипотезе,
что на запад или восток идут не составы, а отдельные вагоны
(отличающиеся типом и грузом), а состав идет туда же, куда
и большинство вагонов.
2-й вариант соответствует гипотезе,
что составы как бы не состоят из различных вагонов с различными
грузами, а свойства вагонов и грузов являются свойствами непосредственно
состава.
Необходимо отметить, что сравнительно
небольшое количество признаков вагонов обеспечивает огромное
количество различных типов вагонов, из которых реально в приведенных
составах встречается лишь незначительная часть. Очевидно, существует
еще большее количество вариантов сочетаний различных типов
вагонов с различными грузами, следования их друг за другом
и т.п..
Из этого следует по крайней мере два
основных вывода:
1. Составить исчерпывающий справочник
для описания состава на 2-м уровне, в котором бы указывались
все варианты сочетаний различных типов вагонов с различными
грузами на практике довольно трудоемко и вряд ли нецелесообразно
(из-за его огромной размерности).
2. Реально встречающиеся в составах
сочетания типов вагонов и видов грузов практически все будут
являться уникальными, что обеспечит однозначную идентификацию
составов, если их описывать только на 2-м уровне. Это превращает
задачу в тривиальную. Поэтому будем рассматривать описание
составов на 3-м уровне с элементами 2-го.
Вербальные описания железнодорожных
составов практически на естественном языке являются их лингвистическими
моделями, которые могут обрабатываться в системе "Эйдос". При
этом в справочники будут заноситься, причем автоматически,
только реально встретившиеся признаки составов.
1. Формализовать задачу, создав классификационные
и описательные шкалы с использованием таблицы 1 и обучающую
выборку на основе рисунка 1.
2. Осуществить синтез и верификацию
модели.
3. Провести анализ модели, сформулировав
правила для прогнозирования направления движения составов (в
режиме: "Типология", "Информационные портреты
классов").
4. Оценить ценность признаков для
прогнозирования. Выделить признаки, наиболее существенные для
решения поставленной задачи.
5. Сравнить составы по степени "типичности" для
своих кластеров ("Идущие на запад", "Идущие
на восток"). Вывести в графической форме семантические
сети составов, построить классические когнитивные карты для
составов идущих на запад и на восток.
1. Создать стандартизированные с использованием
таблицы 1 текстовые описания составов в виде отдельных
файлов стандарта DOS-текст с концами строк, записать их в поддиректорию
DOB в виде: ####-zap.txt и ####-vos.txt.
2. Сгенерировать классификационные
и описательные шкалы в режиме: "Автоввод первичных признаков
и TXT-файлов", "Признаки – слова".
3. Сгенерировать обучающую выборку
с использованием режима: "Ввод-корректировка обучающей
выборки", "F7 InpTXT", "F6 Ввод из всех
файлов". Дополнить анкеты, соответствующие составам, кодами
принадлежности к обобщенным образам классов: "Идущие на
запад", "Идущие на восток".
4. Осуществить синтез и верификацию
модели.
5. Провести анализ модели, сформулировав
правила для прогнозирования направления движения составов (в
режиме: "Типология", "Информационные портеры
классов").
6. Оценить ценность признаков для
прогнозирования. Выделить признаки, наиболее существенные для
решения поставленной задачи.
7. Сравнить составы по степени "типичности" для
своих кластеров ("Идущие на запад", "Идущие
на восток"). Вывести в графической форме семантические
сети составов, построить классические когнитивные карты для
составов идущих на запад и на восток.
Для этих целей используем таблицу
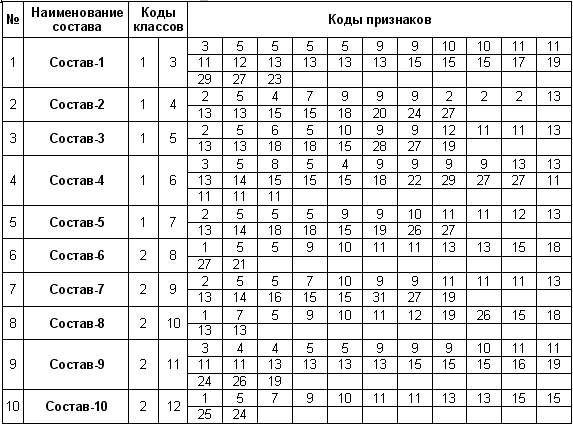
1 и рисунок 1. В результате получим таблицы 2 и 3:
Таблица 2 – КЛАССИФИКАЦИОННЫЕ И ОПИСАТЕЛЬНЫЕ
ШКАЛЫ И ГРАДАЦИИ
Таблица 3 – ОБУЧАЮЩАЯ ВЫБОРКА
Создать стандартизированные с использованием
таблицы 1 текстовые описания составов в виде отдельных файлов
стандарта DOS-текст с концами строк, записать их в поддиректорию
DOB в виде: ####-zap.txt и ####-vos.txt, где #### – номер анкеты
(состава) в виде 0001, 0002 и т.д., а остальные символы произвольные,
но выбираются таким образом, чтобы отражать содержание анкеты.
0001-VOS.TXT
Кол-во_вагонов=4
форма_вагона_прямоугольная
форма_вагона_прямоугольная
форма_вагона_прямоугольная
форма_вагона_прямоугольная
длина_вагона_короткий
длина_вагона_короткий
длина_вагона_длинный
длина_вагона_длинный
N_осей_вагона=2
N_осей_вагона=2
N_осей_вагона=2
N_осей_вагона=3
стенки_вагона_одинарные
стенки_вагона_одинарные
стенки_вагона_одинарные
стенки_вагона_одинарные
крыша_вагона_отсутствует
крыша_вагона_отсутствует
крыша_вагона_отсутствует
крыша_вагона_двухскатная
груз_1_большой_круг
груз_1_шестиугольник
груз_1_треугольник
груз_3_квадрата
0002-VOS.TXT
Кол-во_вагонов=3
форма_вагона_прямоугольная
форма_вагона_V-образная
форма_вагона_U-образная
длина_вагона_короткий
длина_вагона_короткий
длина_вагона_короткий
N_осей_вагона=2
N_осей_вагона=2
N_осей_вагона=2
стенки_вагона_одинарные
стенки_вагона_одинарные
стенки_вагона_одинарные
крыша_вагона_отсутствует
крыша_вагона_отсутствует
крыша_вагона_прямая
груз_2_маленьких_круга
груз_1_короткий_прямоугольник
груз_1_треугольник
0003-VOS.TXT
Кол-во_вагонов=3
форма_вагона_прямоугольная
форма_вагона_прямоугольная
форма_вагона_ромбовидная
длина_вагона_длинный
длина_вагона_короткий
длина_вагона_короткий
N_осей_вагона=3
N_осей_вагона=2
N_осей_вагона=2
стенки_вагона_одинарные
стенки_вагона_одинарные
стенки_вагона_одинарные
крыша_вагона_отсутствует
крыша_вагона_прямая
крыша_вагона_прямая
груз_1_большой_круг
груз_1_треугольник
груз_1_перевернутый_треугольник
0004-VOS.TXT
Кол-во_вагонов=4
форма_вагона_прямоугольная
форма_вагона_прямоугольная
форма_вагона_эллипсоидная
форма_вагона_V-образная
длина_вагона_короткий
длина_вагона_короткий
длина_вагона_короткий
длина_вагона_короткий
N_осей_вагона=2
N_осей_вагона=2
N_осей_вагона=2
N_осей_вагона=2
стенки_вагона_одинарные
стенки_вагона_одинарные
стенки_вагона_одинарные
стенки_вагона_двойные
крыша_вагона_отсутствует
крыша_вагона_отсутствует
крыша_вагона_отсутствует
крыша_вагона_прямая
груз_1_квадрат
груз_1_треугольник
груз_1_треугольник
груз_1_ромб
0005-VOS.TXT
Кол-во_вагонов=3
форма_вагона_прямоугольная
форма_вагона_прямоугольная
форма_вагона_прямоугольная
длина_вагона_короткий
длина_вагона_короткий
длина_вагона_длинный
N_осей_вагона=3
N_осей_вагона=2
N_осей_вагона=2
стенки_вагона_одинарные
стенки_вагона_одинарные
стенки_вагона_двойные
крыша_вагона_отсутствует
крыша_вагона_прямая
крыша_вагона_прямая
груз_1_большой_круг
груз_1_треугольник
груз_1_длинный_прямоугольник
0006-ZAP.TXT
Кол-во_вагонов=2
форма_вагона_прямоугольная
форма_вагона_прямоугольная
длина_вагона_короткий
длина_вагона_длинный
N_осей_вагона=2
N_осей_вагона=2
стенки_вагона_одинарные
стенки_вагона_одинарные
крыша_вагона_отсутствует
крыша_вагона_прямая
груз_3_маленьких_круга
груз_1_треугольник
0007-ZAP.TXT
Кол-во_вагонов=3
форма_вагона_прямоугольная
форма_вагона_прямоугольная
форма_вагона_U-образная
длина_вагона_короткий
длина_вагона_короткий
длина_вагона_длинный
N_осей_вагона=2
N_осей_вагона=2
N_осей_вагона=2
стенки_вагона_одинарные
стенки_вагона_одинарные
стенки_вагона_двойные
крыша_вагона_отсутствует
крыша_вагона_отсутствует
крыша_вагона_гофрированная
груза_нет
груз_1_большой_круг
груз_1_треугольник
0008-ZAP.TXT
Кол-во_вагонов=2
форма_вагона_прямоугольная
форма_вагона_U-образная
длина_вагона_короткий
длина_вагона_длинный
N_осей_вагона=2
N_осей_вагона=3
стенки_вагона_одинарные
стенки_вагона_одинарные
крыша_вагона_отсутствует
крыша_вагона_прямая
груз_1_большой_круг
груз_1_длинный_прямоугольник
0009-ZAP.TXT
Кол-во_вагонов=4
форма_вагона_прямоугольная
форма_вагона_прямоугольная
форма_вагона_V-образная
форма_вагона_V-образная
длина_вагона_короткий
длина_вагона_короткий
длина_вагона_короткий
длина_вагона_длинный
N_осей_вагона=2
N_осей_вагона=2
N_осей_вагона=2
N_осей_вагона=2
стенки_вагона_одинарные
стенки_вагона_одинарные
стенки_вагона_одинарные
стенки_вагона_одинарные
крыша_вагона_отсутствует
крыша_вагона_отсутствует
крыша_вагона_отсутствует
крыша_вагона_гофрированная
груз_1_большой_круг
груз_1_большой_круг
груз_1_длинный_прямоугольник
груз_1_короткий_прямоугольник
0010-ZAP.TXT
Кол-во_вагонов=2
форма_вагона_прямоугольная
форма_вагона_U-образная
длина_вагона_короткий
длина_вагона_длинный
N_осей_вагона=2
N_осей_вагона=2
стенки_вагона_одинарные
стенки_вагона_одинарные
крыша_вагона_отсутствует
крыша_вагона_отсутствует
груз_1_короткий_прямоугольник
груз_2_коротких_прямоугольника
Для этого используем режим: "F1
Словари – Автоввод первичных признаков и TXT-файлов – F3 Признаки
– слова".
Классы во втором задании те же самые,
что и в первом. Признаки выглядят несколько иначе, т.к. формируются
автоматически из текстовых описаний составов, но по сути
они также те же самые (таблица 4):
Таблица 4 – КЛАССИФИКАЦИОННЫЕ И ОПИСАТЕЛЬНЫЕ ШКАЛЫ И ГРАДАЦИИ
Используем режим: "F2 Обучение
– Ввод-корректировка обучающей выборки – F7 InpTXT – F6 Ввод
из всех файлов". Затем необходимо дополнить анкеты, соответствующие
составам, кодами принадлежности к обобщенным образам классов: "Идущие
на запад", "Идущие на восток". Обучающая выборка
будет иметь вид, представленный в таблице 7:
Таблица 5 – ОБУЧАЮЩАЯ ВЫБОРКА
Этапы синтеза модели, ее оптимизации, проверки
адекватности и анализа подробно описаны в работах [2, 3], поэтому
в данной статье мы приведем лишь их результаты.
Пример решения задания 2.4: "Осуществить синтез и верификацию
семантической информационной модели"
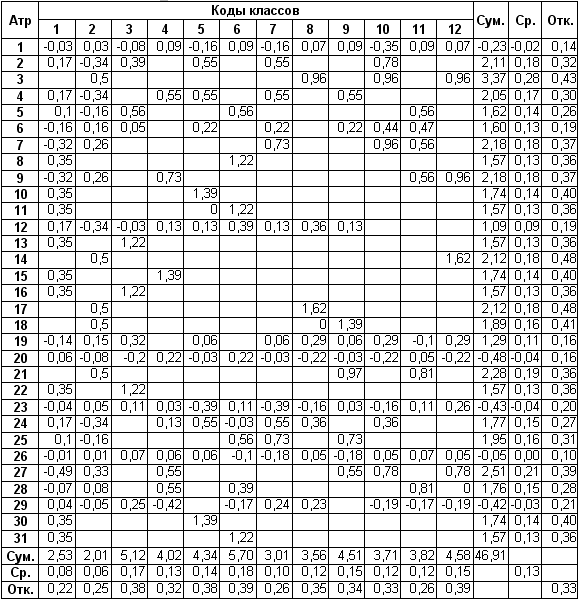
Основная матрица семантической информационной
модели приведена в таблице 6:
Таблица 6 – МАТРИЦА ИНФОРМАТИВНОСТЕЙ
Пример решения задания 2.5 "Провести анализ модели, сформулировав
правила для прогнозирования направления движения составов"
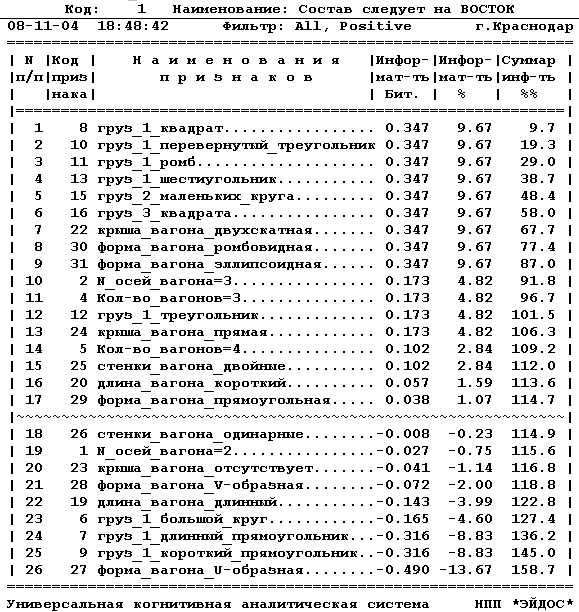
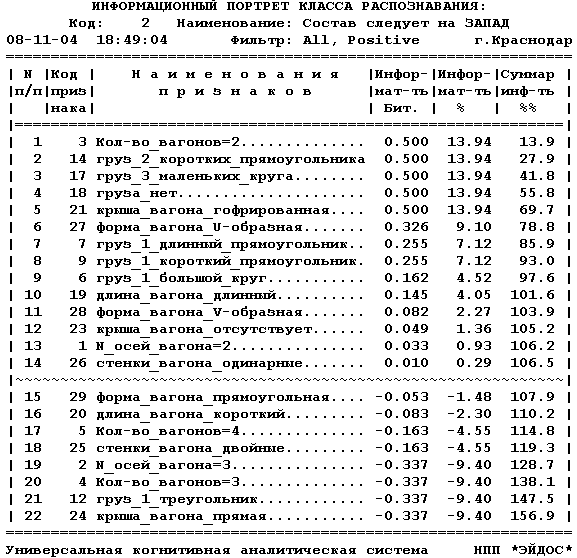
В подсистеме: "Типология", "Информационные
портеры классов" системы "Эйдос" получаем следующие
информационные портреты классов (таблицы 7 и 8):
ТАБЛИЦА 7 - ИНФОРМАЦИОННЫЙ ПОРТРЕТ КЛАССА
РАСПОЗНАВАНИЯ
ТАБЛИЦА 8 - ВЛИЯНИЕ
ПРИЗНАКОВ
НА РЕЗУЛЬТАТ ПРОГНОЗИРОВАНИЯ:
"НАПРАВЛЕНИЕ СЛЕДОВАНИЯ - НА ЗАПАД"
Пример решения задания 2.6: "Оценить ценность признаков для
прогнозирования. Выделить признаки, наиболее существенные для решения
поставленной задачи"
В подсистеме "Оптимизация" режиме " режиме "Исключение
признаков с низкой селективной силой" получаем перечень
признаков, ранжированных в порядке убывания среднего количества
информации о направлении следования состава (таблица 9).
Накопительная диаграмма селективной силы
(Парето-диаграмма) приведена на рисунке 2.
 |
Рисунок 2. Парето-диаграмма
ценности признаков для решения задач
идентификации, прогнозирования и управления |
Пример решения задания 2.7: "Сравнить составы по степени
"типичности" для своих кластеров ("Идущие на запад",
"Идущие на восток"). Вывести в графической форме семантические
сети составов. Построить классические когнитивные карты для составов
идущих на запад и на восток"
Сравним составы по степени "типичности" для
своих кластеров ("Идущие на запад", "Идущие
на восток"). В подсистеме "Типология" режиме "Типологический
анализ классов распознавания – Кластерный и конструктивный
анализ – просмотр и печать кластеров и конструктов" выводим
конструкт: "Идущие на запад" и "Идущие на
восток" (рисунки 3 и 4).
 |
| Рисунок 3. Подсистема "Типология",
режим "Типологический анализ классов распознавания
– Кластерный и конструктивный анализ – просмотр и печать
кластеров и конструктов" |
 |
| Рисунок 4. Конструкт: "Идущие
на запад" и "Идущие на восток" |
Из рисунка 4 видно, что:
– составы 4-й, 1-й и 3-й являются
типичными для "Идущих на восток", а 5-й и особенно
2-й – нетипичными;
– составы 10-й, 9-й и 8-й являются
типичными для "Идущих на запад", а 7-й и особенно
6-й – нетипичными.
Выведем в графической форме семантические
сети составов.
Семантические сети классов отображают
результаты кластерно-конструктивного анализа в графической
форме. Для этого используется режим: "Вывод 2d-семантических
сетей классов" (рисунок 3). Результат приведен на рисунке
5.
 |
| Рисунок 5.
Семантическая сеть классов |
Построим классические когнитивные
карты для составов идущих на запад и на восток". В
Системе "Эйдос" классическая когнитивная карта
строится из двух графических диаграмм:
1. Неклассического нейрона (подсистема "Анализ",
режим "Графическое отображение нелокальных нейронов",
рисунок 6);
2. Семантической сети признаков (подсистема "Типология",
режим "Кластерный и конструктивный анализ признаков –
вывод 2d-семантических сетей признаков",
рисунок 7).
 |
 |
| Рисунок 6. Задание
режима отображения нелокальных нейронов |
Рисунок 7. Задание
режима отображения семантических сетей признаков |
Результаты, т.е. когнитивные карты
для составов, идущих на восток и запад приведены на рисунках
8 и 9.
 |
 |
 |
 |
Рисунок 8. Когнитивная
карта
для составов, идущих на восток |
Рисунок 9. Когнитивная
карта
для составов, идущих на восток |
Из рисунков 8 и 9 видно, что классическая
когнитивная карта может быть изображена в форме конуса, но
для наглядности изображения большого объема информации его
вершина и боковая поверхность показана в форме нейрона, а основание
– в форме семантической сети.
Выводы
Таким образом, вербальные описания объектов реальности на естественном
языке с полным основанием могут рассматриваются как их иерархические
лингвистические модели. Вербальные описания объектов реальности на естественном языке
рассматриваются в статье как их иерархические лингвистические модели.
Предложены методика и автоматизированная технология, основанные
на применении универсальной когнитивной аналитической системы "Эйдос",
обеспечивающие: автоматизированную формализацию предметной области
на основе вербального описания ее объектов, автоматизированное формирование
описательных шкал и градаций, а также обучающей выборки, синтез
семантической информационной модели, ее оптимизацию, проверку адекватности
и анализ. Предлагаемые технологии обеспечивают значительную экономию
труда и времени по сравнению с традиционным подходом.
Литература
1. Мичи Д., Джонстон Р. Компьютер – творец.
–М.: Мир, 1987. -251 с.
2. Луценко Е.В. Автоматизированный системно-когнитивный
анализ в управлении активными объектами (системная теория информации
и ее применение в исследовании экономических, социально-психологических,
технологических и организационно-технических систем): Монография
(научное издание). –Краснодар: КубГАУ. 2002. – 605 с.
3. Луценко Е.В. Теоретические основы
и технология адаптивного семантического анализа в поддержке
принятия решений (на примере универсальной автоматизированной
системы распознавания образов "ЭЙДОС-5.1"). – Краснодар:
КЮИ МВД РФ, 1996. – 280 с.
| 
 English
English


 Версия для печати
Версия для печати Файл в формате pdf
Файл в формате pdf